De technologische vooruitgang op het gebied van kunstmatige intelligentie, ook bekend als artificial intelligence of kortweg AI, verloopt in een razend tempo en heeft inmiddels een prominente positie verworven in ons alledaagse bestaan. Binnen het bedrijfsleven kan AI eveneens van onschatbare waarde zijn bij het uitvoeren van dagelijkse werkzaamheden, zoals:
Als freelance data scientist en machine learning engineer bied ik mijn expertise aan om zowel individuen als bedrijven te ondersteunen bij de ontwikkeling en implementatie van schaalbare AI-oplossingen.
Als data scientist ben ik gespecialiseerd in het verzamelen, analyseren en interpreteren van grote hoeveelheden gegevens om waardevolle inzichten en besluitvorming te genereren. Ik maak gebruik van geavanceerde analytische technieken, statistische modellen en programmeervaardigheden om complexe datasets te verkennen, patronen te ontdekken en voorspellende modellen te ontwikkelen.
Mijn werk omvat het formuleren van onderzoeksvragen, het identificeren van relevante gegevensbronnen en het ontwerpen en implementeren van experimenten. Ik analyseer de resultaten en presenteer complexe informatie op een begrijpelijke manier aan belanghebbenden zonder technische achtergrond.
Om succesvol te zijn in mijn rol als data scientist, beschik ik over sterke vaardigheden op het gebied van probleemoplossing, kritisch denken en communicatie. Ik blijf voortdurend op de hoogte van de nieuwste ontwikkelingen en technologieën in mijn vakgebied, aangezien data science voortdurend evolueert.
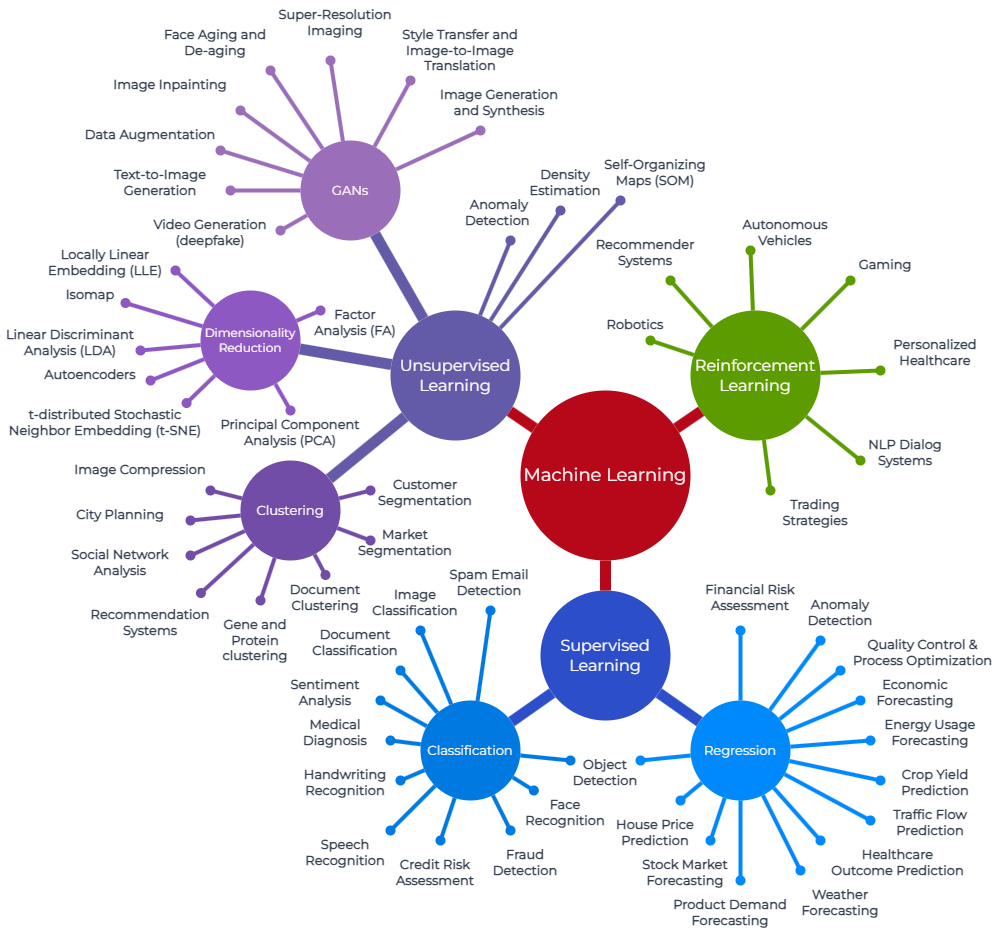
Als machine learning engineer ligt mijn expertise in het ontwerpen, implementeren en optimaliseren van machine learning-algoritmen en modellen. Ik combineer mijn kennis van computerwetenschappen, wiskunde en statistiek om computersystemen te trainen en te leren hoe ze taken kunnen uitvoeren zonder expliciet geprogrammeerd te worden.
Als machine learning engineer heb ik een diepgaand begrip van verschillende machine learning-technieken, zoals supervised learning, unsupervised learning en reinforcement learning. Ik werk daarbij met de programmeertaal Python en tools zoals TensorFlow, Keras, lightGBM, XGBoost en scikit-learn om complexe algoritmen te ontwikkelen en te implementeren.
Mijn verantwoordelijkheden omvatten onder andere het verzamelen en analyseren van gegevens, het selecteren van de juiste algoritmen voor een specifieke taak, het trainen en valideren van modellen, het optimaliseren van de prestaties en het implementeren van de modellen in productiesystemen. Daarnaast ben ik in staat om problemen met betrekking tot ‘class imbalance’, overfitting en dataverzameling aan te pakken en oplossingen te vinden.
Naast mijn technische vaardigheden heb ik sterke probleemoplossende en analytische vaardigheden. Ik ben in staat om complexe problemen te begrijpen, creatieve oplossingen te bedenken en resultaten op een begrijpelijke manier te communiceren aan zowel technische als niet-technische belanghebbenden.
In de snel evoluerende wereld van machine learning blijf ik constant bezig met het bijhouden van de nieuwste onderzoeken, technologieën en best practices om op de hoogte te blijven van de meest effectieve en efficiënte methoden.
Hieronder staan een aantal van de projecten omschreven waar ik zelfstandig of in teamverband aan heb gewerkt in de afgelopen jaren. Het betreft hier twee sport gerelateerde data science projecten uitgevoerd voorafgaande en tijdens mijn periode bij SciSports en een selectie van de deep learning projecten uit mijn periode bij Datacadabra. Voor ieder project zijn labels toegevoegd die aangeven welke technieken hiervoor gebruikt zijn.
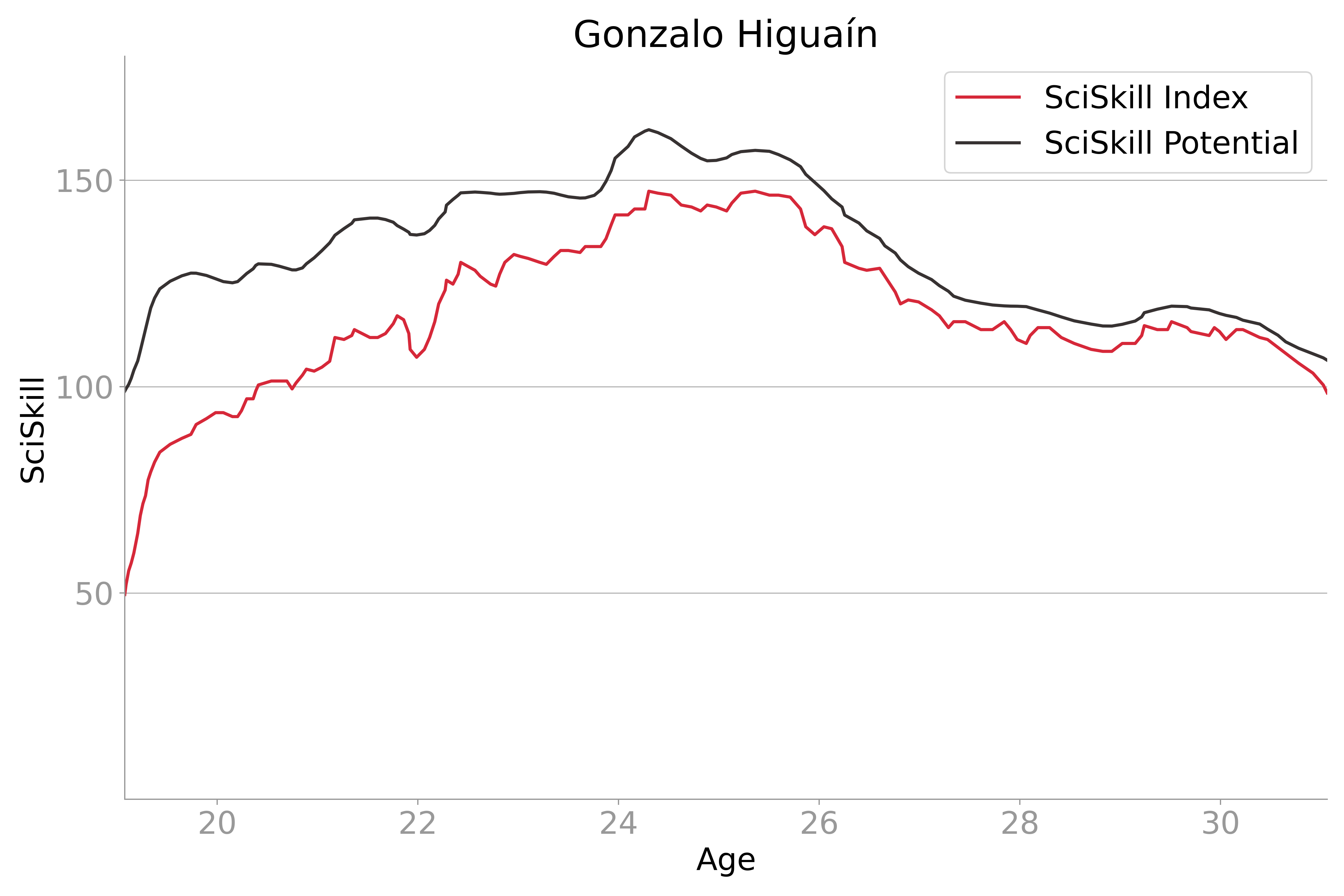
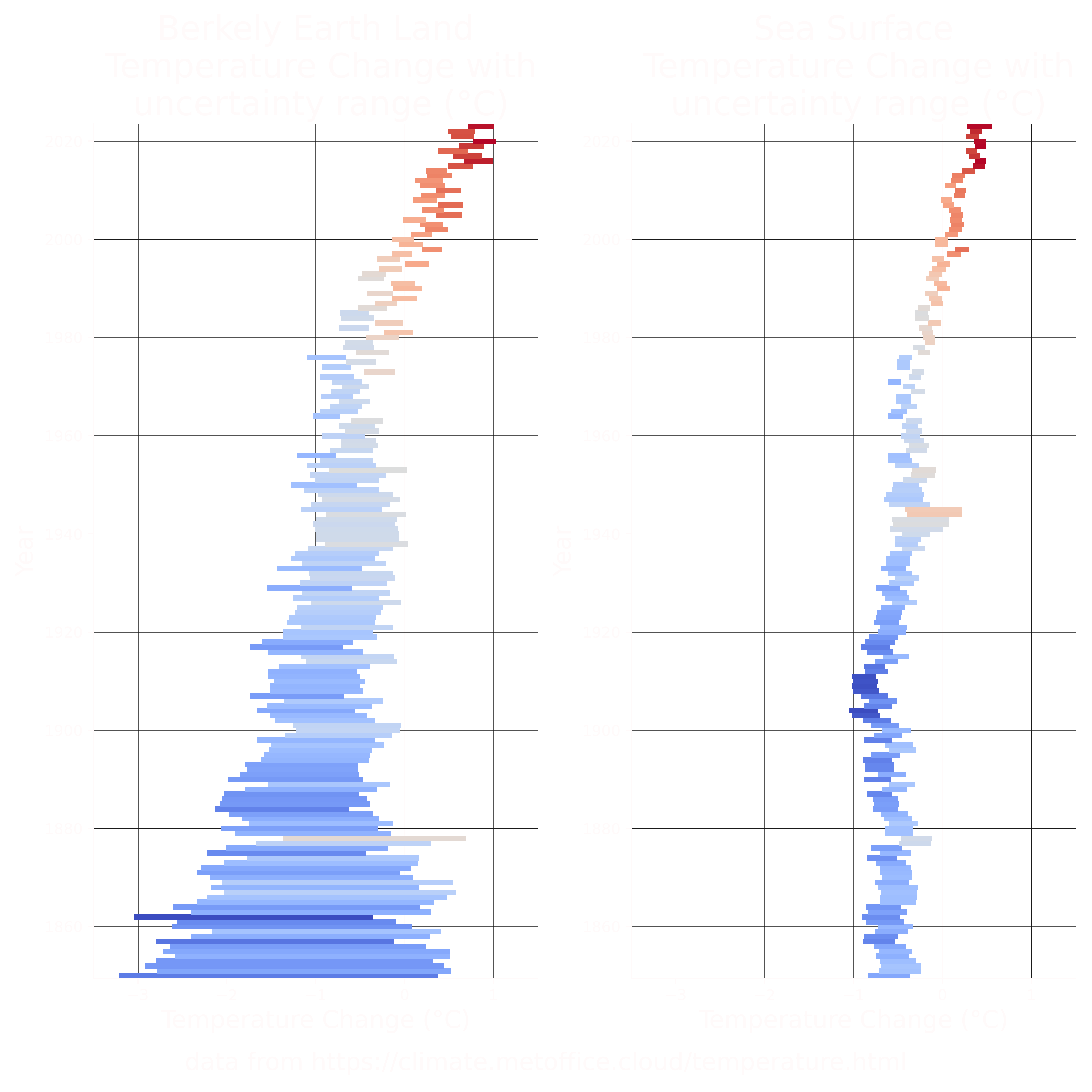
De SciSkill Index geeft voetbalclubs de mogelijkheid om spelers te rangschikken op basis van de bijdrage die ze hebben geleverd aan het resultaat op het veld. Dit algoritme maakt gebruik van enkel wedstrijduitslagen, spelersposities en speelminuten en update de index van iedere speler afzonderlijk op basis van de vooraf verwachte en de daadwerkelijke bijdrage aan het eindresultaat resultaat. Op deze manier worden circa 200.000 spelers gerangschikt, waarmee onder andere voetbalscouts snel en eenvoudig een shortlist kunnen maken van potentieel interessante spelers.
Op basis van de beschikbare historische data is met behulp van een regressiemodel de SciSkill Potential ontwikkeld. Dit algoritme maakt een inschatting van het potentieel van een speler op basis van het historisch verloop van de SciSkill Index van oudere en oud spelers.
Zwerfvuil is een groot probleem zowel wereldwijd als ook in Nederland. Mede om die reden heeft Datacadabra via een aanbesteding van de Provincie Overijssel de Mowhawk ontwikkeld. De Mowhawk is een met AI uitgerust camerasysteem dat wordt bevestigd op de maaimachines die de bermen langs de wegen maaien. Binnen het verzamelde beeldmateriaal wordt real-time gedetecteerd of er vuil of invasieve exoten aanwezig zijn en wordt de route van de maaimachine geregistreerd. Deze informatie wordt vervolgens opgeslagen in een cloudomgeving en geëxporteerd naar kaartlagen die in te lezen zijn in het Geo-informatiesysteem (GIS) van de klant.
In dit ontwikkeltraject heb ik mij onder andere beziggehouden met de ontwikkeling van het detectiesysteem voor vuil. Hiervoor is gebruikgemaakt van deep learning, waarbij een pipeline is opgezet voor het trainen van het model. Ter voorbereiding is hiervoor een model architectuur ontworpen en een geschikte ‘loss’ functie gedefinieerd. Binnen deze pipeline wordt de data geprepareerd, opgesplitst in een training en validatie set, wordt het model gecompileerd, getraind en worden de eindresultaten geëvalueerd.
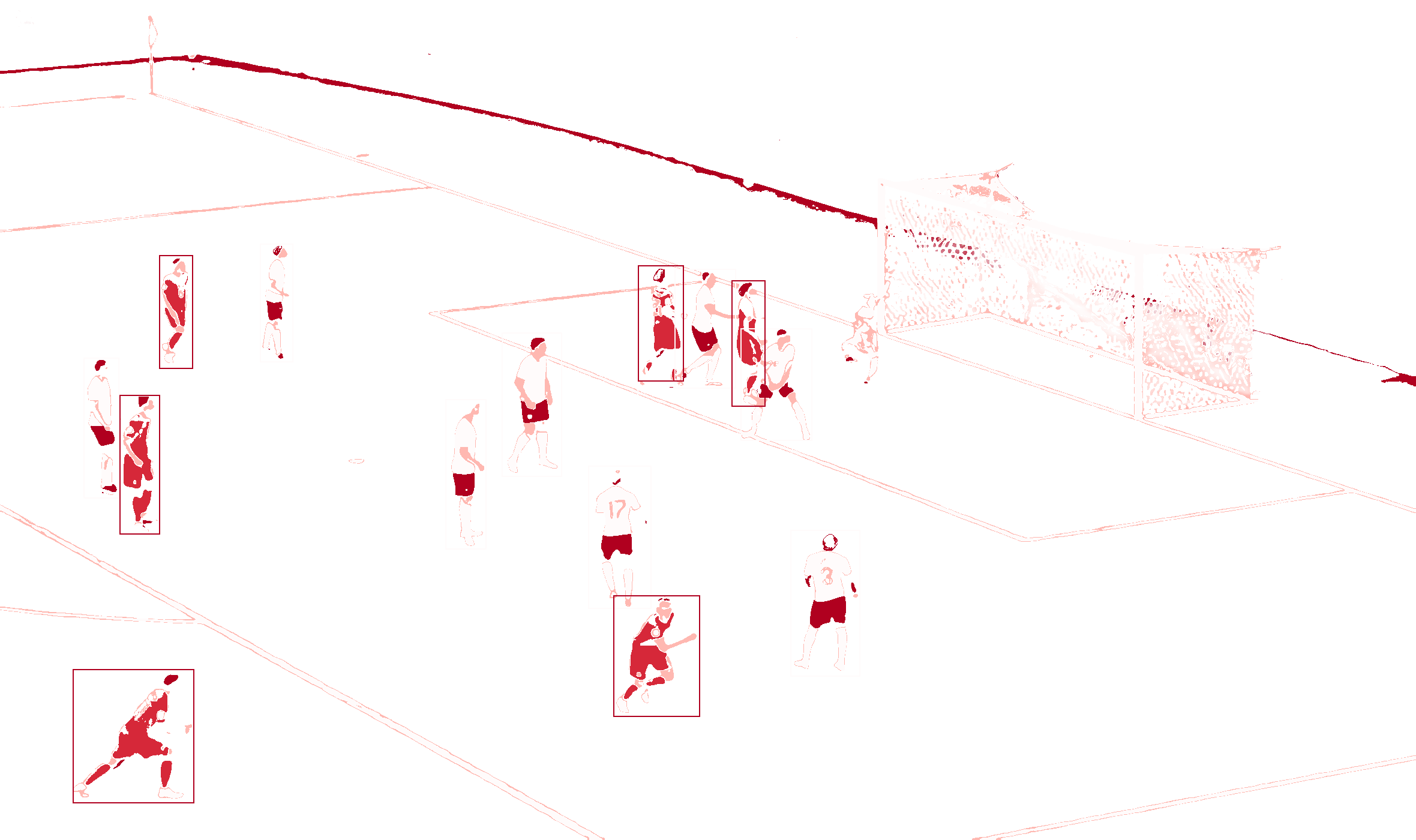
Zwerfvuil detectie op basis van camerabeelden. De waarde in de hoek links boven in ieder vak geeft de waarschijnlijkheid aan waarmee vuil wordt gedetecteerd. Bij een waarschijnlijkheid groter dan 0.75, ofwel 75%, wordt een kader om het vak getekend.

Mobile mapping is een snelgroeiend domein dat gebruikmaakt van geavanceerde technologieën om gegevens vast te leggen en geografische informatie te verzamelen vanuit bewegende voertuigen. De beelden die verzameld worden met dit soort systemen bevatten ook privacygevoelige informatie, zoals nummerplaten en gezichten van personen, die veelal nog handmatig worden geanonimiseerd.
Voor een mobile mapping partij heb ik meegewerkt aan een oplossing om deze privacygevoelige informatie automatisch te verwijderen uit het beeldmateriaal. Hiervoor is een pipeline ontwikkeld met onder andere een module voor het detecteren van nummerplaten. Hiervoor is gebruikgemaakt van deep learning, waarbij een pipeline is opgezet voor het trainen van het model. Ter voorbereiding is hiervoor een model architectuur ontworpen en een geschikte ‘loss’ functie gedefinieerd voor het detecteren van objecten. Daarbij wordt enerzijds een classificatie uitgevoerd die aangeeft of er wel of geen object is gedetecteerd. Anderzijds worden middels regressie de coördinaten van de ‘bounding box’ geschat.In de context van objectdetectie en computer vision wordt een bounding box gebruikt om een rechthoekig kader rond een object in een afbeelding te tekenen, waardoor het object visueel wordt begrensd en gelokaliseerd voor verdere verwerking. Binnen deze pipeline wordt de data geprepareerd, opgesplitst in een training en validatie set, wordt het model gecompileerd, getraind en worden de eindresultaten geëvalueerd.
In de afgelopen decennia is het wervingsproces van spelers in het professionele voetbal geëvolueerd tot een miljardenindustrie. Om inzicht te krijgen in het algemene niveau van hun potentiële versterkingen, hebben veel professionele voetbalclubs toegang tot uitgebreid videomateriaal en geavanceerde statistieken. De moderne professionele voetbalclubs hebben tegenwoordig een geheel eigen speelstijl, vaak gedeeltelijk of grotendeels bepaald door de hoofdtrainer. Dit betekent dat nieuwe spelers niet alleen moeten beschikken over voldoende talent, maar ook moeten passen binnen de huidige speelstijl van een club.
Om scouts te assisteren in deze zoektocht zijn er op basis van onderliggende data, een uitgebreide zoektocht in sportmedia en in samenspraak met de scouting afdeling in totaal 21 spelersprofielen gedefinieerd. De meeste spelersprofielen beschrijven spelers die uitblinken in technische vaardigheden, voetbalintelligentie, kracht, snelheid en/of uithoudingsvermogen.
Voor het model hebben de data scouts bij SciSports een deel van de dataset met spelers voorzien van labels. Deze labels zijn vervolgens gebruikt om voor ieder spelersprofiel een apart classificatiemodel te trainen. Voor de integratie in het Insight platform is hiervoor een pipeline opgezet, waarmee het mogelijk werd om play-by-play event data direct te verwerken tot spelersprofielen.
Mobile mapping is een geavanceerde technologie die wordt ingezet om gegevens van de omgeving te verzamelen tijdens de verplaatsing van een voertuig door een bepaald gebied. Het voertuig is voorzien van geavanceerde sensoren, zoals LiDAR (Light Detection and Ranging), camera's en GPS, waarmee 3D-gegevens en beelden worden vastgelegd van de omringende wereld. Als onderdeel van een team heb ik gewerkt aan een project waarin een pipeline is ontwikkeld om ondergronden te detecteren binnen de camerabeelden. Deze detecties worden vervolgens omgezet in 2D-geografische coördinaten.
Binnen dit project lag mijn focus voornamelijk op het onderdeel van de pipeline dat beelden verwerkt en ondergronden segmenteert. Daarbij heb ik een model architectuur ontworpen en uitgewerkt en een aangepaste 'loss'-functie ontwikkeld. Deze elementen zijn geïntegreerd in een pipeline voor het trainen van het model, waarbij beelden worden voorbereid en opgedeeld in een training- en validatieset. Het model wordt gecompileerd, getraind en geëvalueerd.
Daarnaast heb ik een pipeline opgezet om nieuwe beelden te verwerken met behulp van het getrainde model, en deze pipeline is geïntegreerd in de gebruikersinterface (GUI) om het gebruiksvriendelijk te maken. Het uiteindelijke resultaat is een effectieve en efficiënte methode om ondergronden automatisch te detecteren en te lokaliseren in mobile mapping beelden, wat waardevolle informatie oplevert voor verschillende toepassingen, zoals stadsplanning, infrastructuurontwikkeling en verkeersanalyse.


Livup is een innovatief datagedreven woningplatform dat openbare databronnen op een intelligente wijze integreert. Door deze databronnen te benutten, wordt voor elke woning in Nederland een specifiek woningprofiel samengesteld, waardoor gebruikers de mogelijkheid krijgen om hun ideale huis te vinden binnen het uitgebreide woningbestand van Nederland.
Binnen Livup heb ik onder andere gewerkt aan de ontwikkeling van de Nationale Woning Index (NWI), een maatstaf die de kwaliteit van woningen beoordeelt. Deze index biedt de mogelijkheid om alle woningen in het beschikbare aanbod te rangschikken, waarbij het unieke aspect is dat de index ongevoelig is voor prijsveranderingen.
De NWI is afgeleid van een specifieke subset van woningwaarden die binnen een kort tijdsbestek zijn geregistreerd. Deze afgeleide dient als de doelvariabele, waarvoor een model is gecreëerd dat op basis van openbare gegevens van elke woning deze doelvariabele zo nauwkeurig mogelijk benadert. Om dit te bereiken, is er gebruikgemaakt van regressie en is er een geavanceerde pipeline opgezet voor het trainen van het model en het fine-tunen van hyperparameters. Binnen deze pipeline wordt de data voorbereid, wordt het model getraind middels cross-validation, en worden de eindresultaten grondig geëvalueerd.
Door globalisering en klimaatverandering heeft Nederland een groeiend probleem met de verspreiding van invasieve exotische planten en dieren. Naast het verdringen van inheemse soorten, veroorzaken sommige van deze invasieve soorten schade aan de infrastructuur, wegen en waterwegen. Om deze uitdaging aan te pakken, is de Mowhawk ontwikkeld als een geavanceerd camerasysteem, voorzien van kunstmatige intelligentie, dat wordt geïnstalleerd op de maaimachines die de bermen langs de wegen onderhouden.
Een belangrijk doel van de Mowhawk is om in real-time de aanwezigheid van invasieve plantensoorten, zoals de Japanse Duizendknoop en/of Reuzenberenklauw, te detecteren binnen het verzamelde beeldmateriaal. Deze waardevolle informatie wordt vervolgens opgeslagen in een cloudomgeving en geëxporteerd naar kaartlagen die kunnen worden geïntegreerd in het Geo-informatiesysteem (GIS) van de klant.
Binnen dit ontwikkeltraject heb ik gewerkt aan de ontwikkeling van het detectiesysteem voor invasieve exoten. Voor deze taak heb ik gebruikgemaakt van deep learning-technieken, waarbij we een solide pipeline hebben opgezet voor het trainen van het model. Ik was verantwoordelijk voor het ontwerpen van de model architectuur en het definiëren van een geschikte 'loss'-functie om het leerproces te optimaliseren. Om het model voor te bereiden, hebben we de relevante data zorgvuldig voorbewerkt en vervolgens opgesplitst in een training- en validatieset. Het model is gecompileerd en getraind, en ten slotte hebben we de eindresultaten uitgebreid geëvalueerd om te verzekeren dat het systeem nauwkeurig en betrouwbaar is in zijn detectiemogelijkheden.
Detectie van invasieve exoten op basis van camerabeelden. De waarde in de hoek links boven in ieder vak geeft de waarschijnlijkheid en het type invasieve exoot dat wordt gedetecteerd. Bij een waarschijnlijkheid groter dan 0.75, ofwel 75%, wordt een kader om het vak getekend.
Mijn naam is Bart Aalbers en ik ben sinds september 2023 werkzaam als freelance data scientist en machine learning engineer. Ik ben in 2007 als werktuigbouwkundige afgestudeerd aan de Universiteit Twente in de biomedische richting. Tijdens mijn studie heb ik me meer verdiept in data-analyse en heb tijdens mijn afstudeeronderzoek gewerkt met een tracking meetsysteem voor het registreren en analyseren van de menselijke loopbeweging.
Mijn carrière ben ik begonnen bij het ingenieursbureau DGMR. Binnen de vakgroep trillingstechniek en geluidarm construeren heb ik me onder andere bezig gehouden met dynamisch gedrag van gebouwen, beheersing van installatiegeluid binnen gebouwen en trillingsisolerende opstellingen van apparaten. Daarnaast mocht ik werken aan enkele meer exotische projecten, zoals het in situ uitvoeren van winddrukmetingen aan de hoogbouw in het centrum van Den Haag. In deze periode van 8 jaar heb ik veel geleerd op het gebied van data-analyse en dit heeft er mede aan bijgedragen dat ik de overstap heb gemaakt naar mijn eerste functie als data scientist.
Bij SciSports heb ik mijn hobby voetbal kunnen combineren met mijn werk als data scientist. Daarbij ben ik van Matlab overgestapt op Python en heb ik mij bijgeschoold op het gebied van machine learning door diverse cursussen te volgen. Ik heb in die periode onder andere de SciSkill Index ontwikkeld waar nog steeds veel clubs dankbaar gebruik van maken. Ik heb hier in totaal 4 jaar met veel plezier gewerkt en in die tijd is het bedrijf uitgegroeid van 5 naar meer dan 50 werknemers.
Vanaf 2019 heb ik gewerkt als lead data scientist bij Datacadabra. Dit is net als SciSports in de beginfase een kleine startup op de Universiteit Twente die AI toepassingen ontwikkelt voor bedrijven en overheden. In deze periode heb ik mijn kennis meer kunnen verbreden op het gebied van deep learning en computer vision. Daarnaast heb ik leiding gegeven aan een klein team van data scientists binnen de multidisciplinaire projecten.
Na enkele jaren te hebben gewerkt als lead data scientist heb ik in juni 2023 besloten om te gaan starten als freelancer, wat voor mij een logische stap is na 8 jaar werken in startups. Ik kijk er naar uit om samen te werken aan mooie nieuwe projecten en uitdagende problemen op te lossen. Als je op zoek bent naar een enthousiaste, ervaren en betrokken data scientist, neem dan gerust contact met me op. Laten we samen kijken of we jouw data kunnen transformeren in waardevolle kennis en inzichten.